
A Prediction Machine
Exploring AI Engineering

We need to talk.
I really can’t see a future in this anymore.
(Dramatic pause)
Zoltar the Fortune teller can though. (What?)
Let’s close our eyes and go back to a happier time.
There’s a strange fair in town. You and the neighbourhood kids are running around like crazy, trying out all the attractions, high on candy floss and slush puppies. (Great times)
In one corner, always a bit to the side, there was this box with some Tim Burton-esque dark cloud hanging over it.
It could have been Zoltar, Esmeralda or any other random mystical-sounding name.
The concept was always the same.
Feed it a coin and this human-like (definitely uncanny valley) robo-clairvoyant gives you a fortune.
It’s a prediction machine.
Not so different from how today’s Generative AI works.
Let’s break it down.
Generative AI
People often use terms like Artificial Intelligence, Machine Learning, Deep Learning and Generative AI interchangeably, but they are not the same.
As you can see in the Venn diagram below they’re nested within each other.
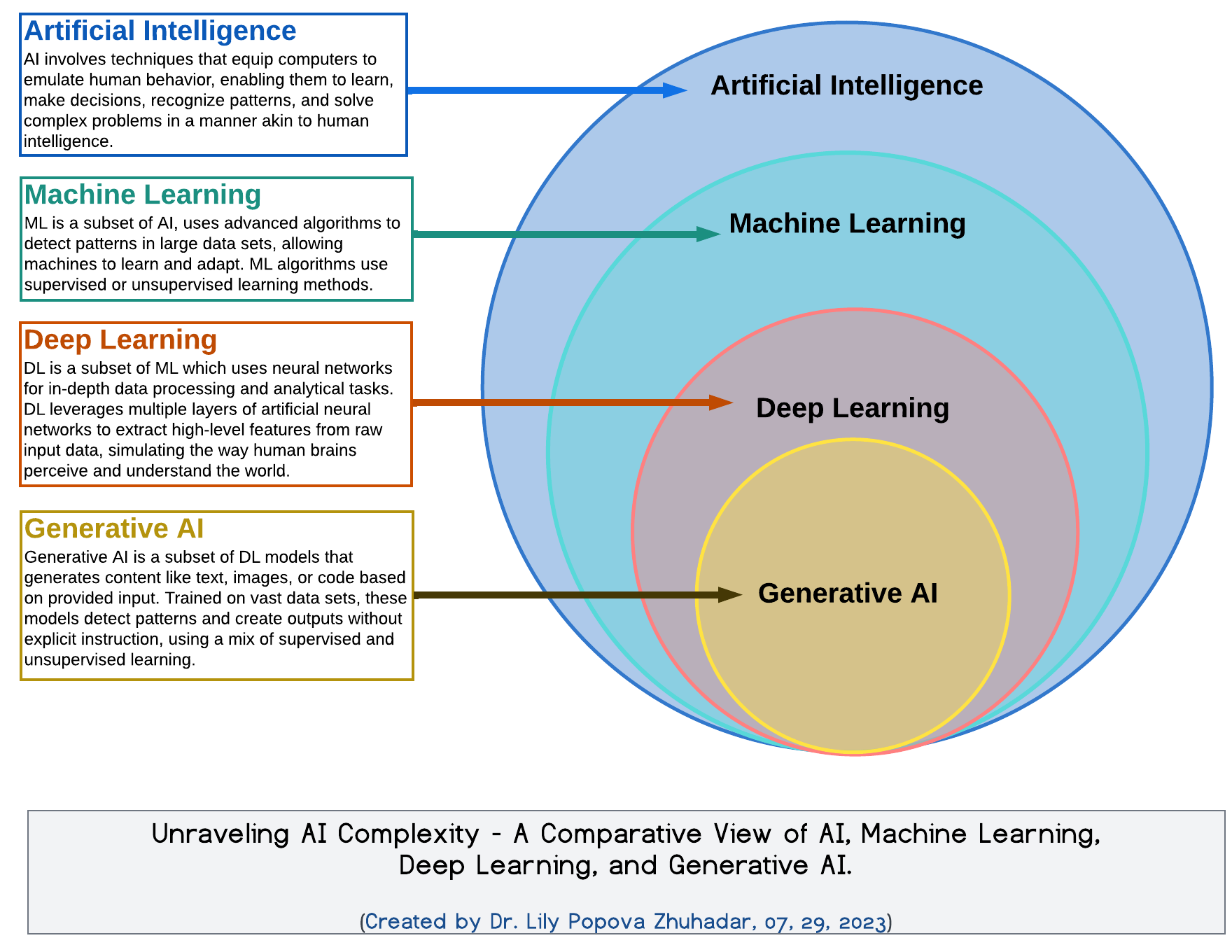
Unlike Zoltar, which is deterministic with a fixed set of predictions, Generative AI actually creates new ones.
It’s probabilistic, or stochastic (beautiful word), which means you won’t always get the same answer.
Think of talking to a brilliant friend that now and then goes on a hallucinatory ayahuasca retreat in Peru. Interesting, but not always connected to reality.
It’s a distinction that separates Generative AI from traditional software development and why the role of AI Engineer is emerging as its own branch.
CPU vs GPU
In the last post, we touched upon transformers, the Deep Learning architecture that started the entire Generative AI revolution.
Before transformers, AI models were trained on CPUs, processing computations one step at a time.
Training could drag on for weeks or even months.
With the new architecture, training could finally be done in parallel, using GPUs instead of CPUs.
This was a huge leap in both speed and scale which allowed for the general-purpose models we see today.
Now the American hardware manufacturer NVIDIA’s stock went straight through the roof and their CEO Jensen Huang (Steve Jobs meets Bono) became tech guru of the day.

Models
AI models are more than pretty faces with bad attitudes. (Oh, yes I did)
This is how IBM defines AI models:
”An AI model is a program that has been trained on a set of data to recognize certain patterns or make certain decisions without further human intervention.”
But it’s not an algorithm.
What's the difference? Think of algorithm as the recipe and the model as the newly baked cake straight from the oven.
Let’s zoom in closer on the models in Generative AI.
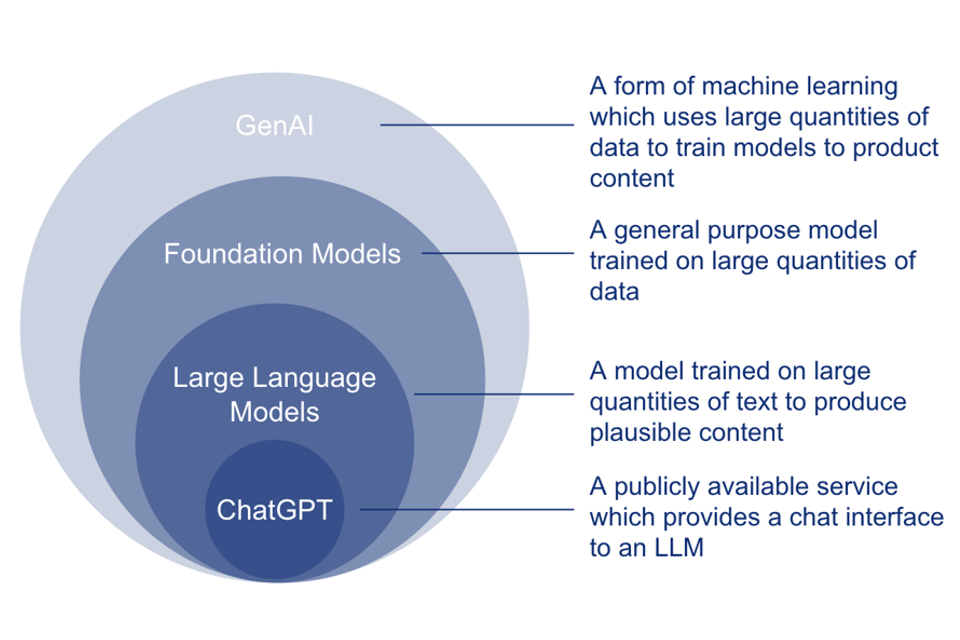
Yep, you guessed it. It’s a Venn diagram:
And listen to Kate Soule from IBM explain how the models work:
At the base layer of we have Foundation Models.
These models are pre-trained in what’s called a self-supervised manner on a huge amount of data.
It means they have learned the patterns on their own without humans labeling the data.
Let’s say they are capable of handling a wide variety of tasks but are still a bit vague.
A Large Language Model (LLM) is basically a text-based foundation model. It’s trained to understand and generate human language.
Some of today’s best-known LLMs are OpenAI’s ChatGPT which belongs to the GPT (Generative Pre-Trained Transformers) family.
After pre-training LLMs can be fine-tuned for specific tasks or guided by prompt engineering.
I think this is the interesting part. Where the actual magic happens.
And that’s what we’ll look at in the next post.
That’s my prediction, anyway.